



Data quality is the second biggest reason why almost 80% of AI projects fail, the first being a lack of right decision-making by a company’s leadership.
AI is only as good as the data it learns from. Feed it junk, and it will confidently make mistakes at scale.
When AI learns from flawed information, the results are disastrous. The impact is not only theoretical; poor data quality has already led to real-world harm.
What are the other reasons why data quality matters in training AI models?
How does bad data produce bad models? What do you even do to solve the data quality problem? (Spoiler: It’s Grepsr).
We’ll answer all of that, but first, let’s start with the basics.
How Do AI Models Interact with Data?

AI is data-hungry. It both uses and learns from data. There are three main ways this happens.
In supervised learning, the model learns from labeled examples. If the labels are wrong, the model picks up those mistakes. In unsupervised learning, there are no labels, just raw data. The model has to find patterns on its own. Here, bad data leads to meaningless or misleading patterns.
In reinforcement learning, the model interacts with an environment, getting rewarded or penalized for its actions. If the feedback signals are noisy, the model learns the wrong behaviors.
State-of-the-art AI models, like GPT-4o and Grok, primarily rely on self-supervised pre-training, followed by supervised fine-tuning on human instructions, with Reinforcement Learning from Human Feedback (RLHF) for behavioral training.
Now, what happens when you apply these principles at scale?
The Scale Factor for Modern AI
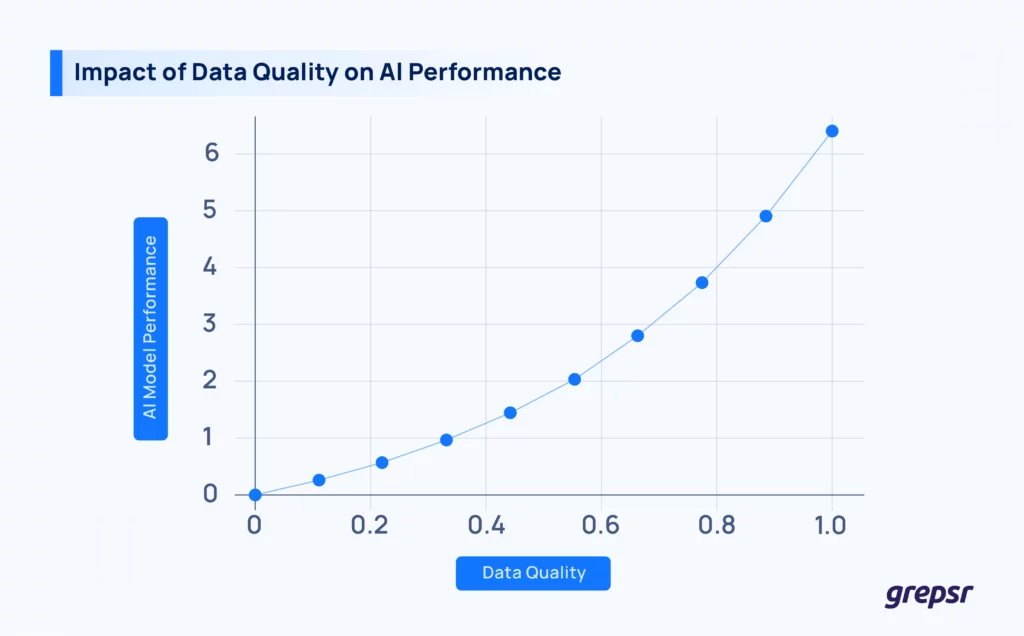
Earlier, AI models were trained on tiny datasets. Now? We’re feeding them massive amounts of web data for training, like ImageNet for vision tasks or Common Crawl for NLP.
The bigger the dataset, the more powerful your model. However, the data quality problem also grows proportionately bigger. More data means better generalization, but only if the data is high quality. If it’s full of junk, your model just memorizes noise at an industrial scale.

Via Reddit
A small error in a dataset of thousands of examples might be manageable, but if you scale that to millions, you’ve created an AI that’s confidently wrong at scale. That’s how we get biased hiring models and chatbots that go rogue.
More data doesn’t always mean better AI—quality beats quantity every time. The best way to always get quality data is to use Grepsr. Grepsr gives you high-quality, accurate scraped data at scale that you can directly feed into your AI model training pipeline.

How to Assess Data Quality for AI?
Data quality ensures your model isn’t making decisions based on nonsense. Here’s what makes or breaks data quality:
- Accuracy: Does the data reflect reality?
- Completeness: Is all the key information present in your data?
- Consistency: Does the data agree across sources?
- Relevance: Are you using the right data for the task?
- Timeliness: How fresh is your data?
But there’s a problem. Data is subjective.
In some cases, noisy data is helpful. A chatbot trained on only perfect grammar won’t understand real-world conversations.
There are trade-offs as well. Would you rather have a small, high-quality dataset or a massive, slightly messy one? It depends on the task. For deep learning, some noise is acceptable. For medical AI? None.
Data quality is everything, but quality depends on the use case.
What Separates High-Quality Data from Low-Quality Data?
Good quality data is not only correct, but it must also be structured, unbiased, and consistently formatted to ensure the AI model can generalize patterns effectively.
Low-quality data introduces inconsistencies, biases, and noise that degrade model performance.
| High-quality data | Low-quality data | |
| Accuracy | Verified against authoritative sources; precise | Contains errors, mislabeling, outdated, or misleading information |
| Completeness | Has the necessary attributes and metadata | Missing critical values, sparse or incomplete records |
| Consistency | Uniform format and standards | Discrepancies between datasets |
| Relevance | Curated for the AI’s domain and task | Contains irrelevant or redundant data, introduces noise and computational waste |
| Timeliness | Frequently updated | Stale or outdated |
| Bias-Free | Balanced, diverse, and representative of real-world distributions | Skewed toward specific demographics |
Why Do You Need Good Data to Train AI Models?
Remember Tay? Within a day, the chatbot started generating offensive content because it learned from a dataset full of human internet behavior: uncurated, unfiltered, and, well, the internet.
That sums up why data quality matters in AI training.
Bad data = Bad AI. Period.
In 2018, Amazon had to scrap an AI-driven hiring tool because it showed bias against women. The dataset it trained on was based on a decade of resumes, which were mostly from men due to historical hiring trends in the tech industry.
The AI wasn’t being sexist on purpose; it was simply reflecting the data it learned from. It reinforced existing biases instead of eliminating them.
In another case, a study found that facial recognition systems from top tech companies had error rates of up to 34% when identifying darker-skinned women compared to nearly 0% for white men. Why? The training datasets were overwhelmingly composed of lighter-skinned faces.
As you can see, bad data has real, grave consequences. Someone can get wrongfully accused, lose a deserving opportunity, or learn outright harmful and false things just because of that.
But is that all?
Poor data quality for AI models can cost you dearly
Training AI isn’t cheap. There’s cloud computing costs, data storage, and engineers working overtime. OpenAI’s GPT-4 cost around $40 million of computing power.
If your AI flops, you have to retrain it, which means more computing power, more time, and more money. And that’s assuming you even realize your model is broken before it goes live.
In 2019, Apple’s credit card algorithm was accused of gender bias when users found that men were being offered significantly higher credit limits than women, even when they had the same financial background. The fallout was severe: regulatory scrutiny, PR disasters, and a loss of trust.
AI bias also leads to lawsuits. In 2020, the state of Michigan was sued because its AI unemployment fraud detection system falsely accused thousands of people of fraud.
More data ≠ better data
More data only helps if it’s good data.
Common Crawl, for example, is one of the largest open datasets used for training AI models, containing years’ worth of web-scraped data.
However, it includes everything: misinformation, spam, outdated sources, and biased narratives. AI models trained on raw web data tend to absorb and amplify misinformation.
In fact, many LLMs that were trained on smaller but high-quality datasets outperform models trained on more but messy data.

Via Reddit
So, what’s the solution? Where do you get good quality, reliable data to train your models?
The answer is Grepsr. With Grepsr, you get clean, structured data without the mess every time.
Grepsr Brings You Quality Datasets to Train Your AI Models (At a Fraction of the Time and Cost)
You could spend weeks collecting data only to find it full of duplicates and missing pieces. Or you could use Grepsr, our data scraping service that does the hard work for you.
Grepsr scrapes the web smartly. We at Grepsr bypass JavaScript blocks, so nothing is hidden from your dataset.
We deliver structured data in Excel, JSON, XML, or another format. The data is clean, ready to use, and accurate with human oversight (because we don’t trust AI to clean up after itself).
Plus, we help you save time and money compared to manual scraping or fixing messy datasets.
If you’re serious about AI training, quality data is the foundation. Get started with Grepsr to get that foundation hassle-free.










































































































